Why AI systems need harnesses, memory discipline, routing, and review gates
By Skaira Labs
Agent Access Is Infrastructure Now
The most important AI architecture decision is often removing AI from part of the system, not because the model is weak, but because some work should never be probabilistic. That decision is becoming more consequential as the agent platform layer matures. A2A v1.0 marks a stable agent-to-agent standard with multi-protocol bindings, multi-tenancy, and signed Agent Cards. The Agentic AI Foundation under the Linux Foundation now anchors projects including the Model Context Protocol, which gives models a standardized interface for connecting to tools, data, and applications. At the same time, lifecycle controls and MCP-specific security work are making permissions, telemetry, context scoping, and tool exposure first-class architecture surfaces. Agent access is becoming infrastructure. That changes where system risk sits.
When access becomes infrastructure, the bottleneck moves to control. The durable advantage is the operating layer around the agent: what deterministic code should own, what model judgment should own, which memory surface is justified at a given scale, which tasks route to which model under which review gate, and which outputs need structural validation versus human approval.
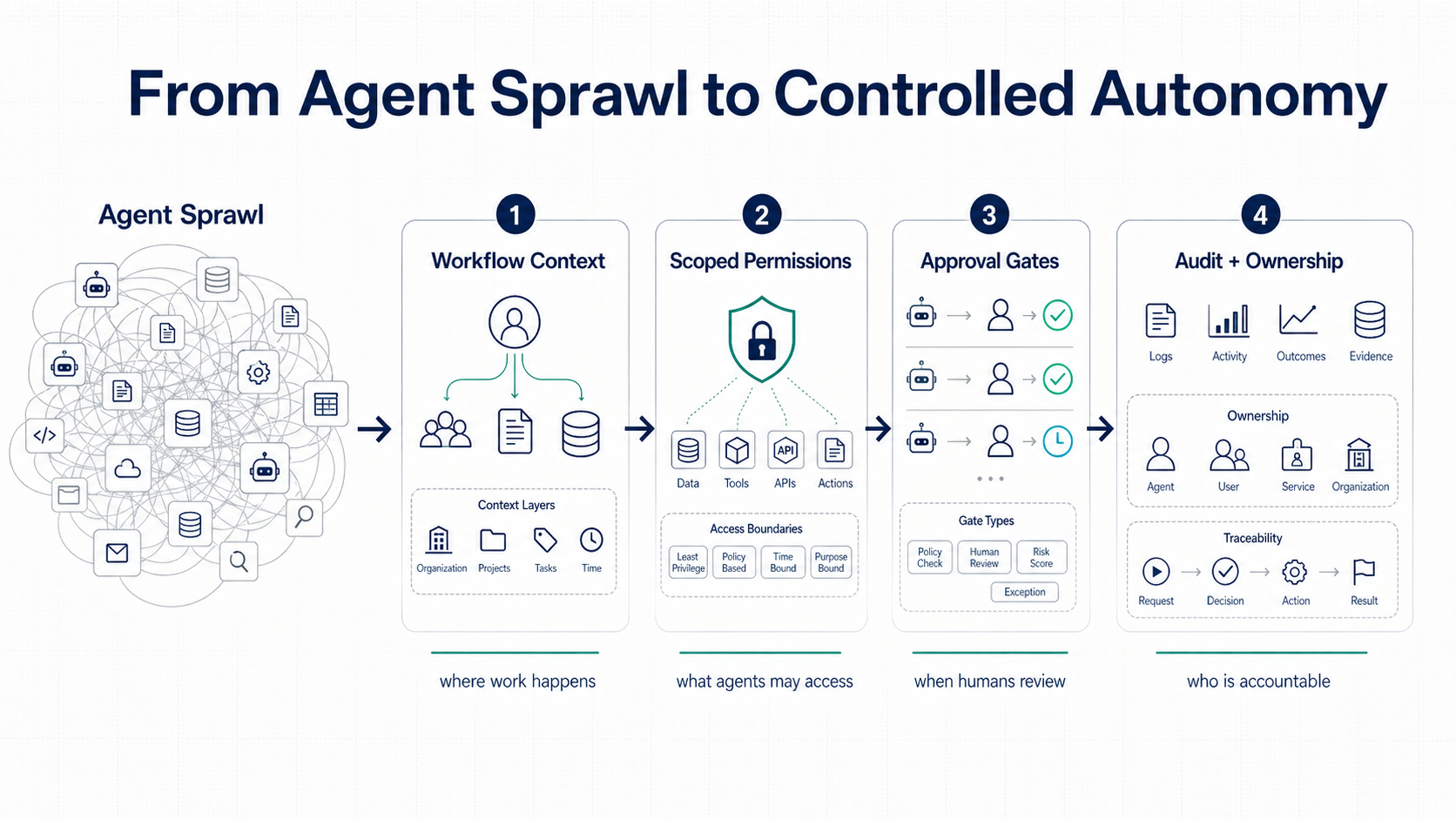
Controlled autonomy needs workflow context, scoped permissions, approval gates, and audit ownership around agents before they touch real operations.
They answer the same operating question: where deterministic control ends, and where bounded model judgment begins.
The Deterministic Boundary
An AI system needs an explicit boundary between deterministic code and model judgment. Code should own the substrate: the parts of the system that the rest of the system has to trust. Models should own bounded judgment: work that requires interpretation, synthesis, or reasoning, constrained by explicit input and output contracts.
| Deterministic code owns | Model judgment owns |
|---|---|
| IDs, state transitions, lineage tracking | Research, synthesis, interpretation |
| Schema validation, structural completeness checks | Prioritization, ambiguity resolution |
| Retries, deduplication, idempotency | Draft generation within scoped contracts |
| Artifact movement, routing eligibility | Exception analysis, cross-domain reasoning |
| Permission checks, audit trail | Bounded judgment with defined inputs and outputs |
A system becomes fragile when models own work that has a known correct answer. It becomes brittle when code tries to own work that requires judgment. The boundary table above should be inspectable in any deployed AI system. In systems that struggle with reliability, this boundary either does not exist or has drifted since the initial design.
Harnesses Enforce the Boundary
A harness is the software layer that keeps the model inside its role. It prepares the context, limits the tools, checks the action before it runs, validates the output after it returns, and decides whether the result can move forward.
The harness pattern has five control surfaces:
| Harness control | What it enforces |
|---|---|
| Pre-action gate | Tool calls or model actions are reviewed before execution: blocked, approved, or modified based on policy. |
| Post-action validation | Output is checked against a structural contract: required fields exist, schema is valid, and forbidden states are absent. |
| Permission boundary | Tool access is scoped per task class so each task gets the minimum system surface it needs. |
| Context isolation | Subtasks operate in bounded context so intermediate state does not leak across unrelated work. |
| Failure handling | Failed or timed-out steps stop, retry, or escalate explicitly instead of continuing silently. |
This pattern is already visible in mature agent tooling. Claude Code's hook surface covers lifecycle events across tool execution, permission control, context management, and task state. The specific tooling will evolve. The architectural pattern generalizes: deployed agent systems are moving toward lifecycle-aware controls that enforce the deterministic boundary at interaction points, not just better prompts.
A reliable architecture for this boundary is a four-stage pipeline: deterministic seed creation by code, bounded model enrichment with explicit input and output contracts, deterministic validation that the output meets the structural contract, and consequence-scaled review before the result moves downstream. Code owns repeatability. The model owns judgment. The handoff between them is inspectable at every stage.
Memory Discipline: Four Patterns, Not One
Most agent frameworks treat memory as a single capability: add a vector store, and the agent remembers. Deployed systems need to distinguish at least four patterns, because each solves a different class of query at a different scale.
Structured file access is the best default when the corpus is small and curated. If the knowledge a system needs fits in a controlled set of files, such as project context, configuration, and operating procedures, the answer is usually better structure and curation, not more infrastructure. Most teams should start here and stay here longer than they expect.
Vector retrieval is useful when the system needs fuzzy recall across a larger artifact set. It handles similarity and discovery well, but it loses relationship structure. A vector store can find documents that are semantically close to a query. It cannot reliably answer which decision superseded an assumption or which artifacts depend on a specific decision.
Code graph memory applies to codebase-specific questions: dependencies, call chains, ownership boundaries, and blast-radius analysis. The Codebase-Memory preprint describes this pattern by using Tree-Sitter to build knowledge graphs for code exploration across 66 languages through MCP. Code has graph-shaped questions that flat search handles poorly. That does not mean every knowledge workflow needs a graph.
Temporal or concept graphs become relevant when the system needs relationship and history queries that exceed what flat retrieval can answer: what changed, what depended on what, which decisions superseded which assumptions, and what was true at a specific point in time.
The discipline is matching the memory surface to the query the system actually needs to answer. At small corpus scale, the bottleneck is usually depth and curation, not retrieval architecture. Switching embedding models or introducing graph-native memory adds operational complexity before it removes a real bottleneck. The stronger pattern is to define scale-based thresholds for when a more complex memory layer becomes worth testing, and to resist deploying infrastructure for a scale that has not been reached.
The most expensive memory architecture mistake is building for a scale you do not have yet.
Routing and Review as Control-Plane Decisions
Which model runs a task, which tools it can access, which trust boundary it operates inside, and which review gate applies are control-plane decisions. They should live in versioned configuration, not in prompt conventions or team habits.
A routing decision should account for at least these dimensions:
- Task class: what kind of work is this?
- Data sensitivity: what classification does the content carry?
- Trust boundary: internal, external-facing, or system/operational?
- Required capabilities: which model and tool profiles match?
- Review gate: what level of validation does this output require?
If those decisions are scattered across application code and prompt templates, they cannot be audited, reproduced, or improved as a system. If every team chooses routes differently, the result is fragmented governance, not flexibility.
The same principle applies to review gates. Not every model output needs human review, but every model output needs a review classification.
Uniform review, applying the same gate to every output, creates gate fatigue and desensitizes the team to the outputs that matter. OWASP's MCP Top 10 project maps why this surface matters: risks such as token exposure, privilege escalation through scope creep, command injection, lack of audit and telemetry, shadow MCP servers, and context over-sharing are operational once agents can use tools at scale. Review gates, permission boundaries, and telemetry are system architecture, not compliance paperwork.
For deeper treatment of these patterns, see why model upgrades are secondary to control-plane governance, why internal and external AI routes should be segregated by design, and how release rings apply to AI governance changes.
What Not to Build
- Do not build graph memory before the corpus justifies it. If the knowledge fits in a structured context window, a graph layer adds operational cost without removing a real bottleneck.
- Do not build universal memory when structured file access or better curation is enough.
- Do not let prompt conventions decide routing. Routing that lives in prompts cannot be audited, versioned, or improved as a system.
- Do not use model calls for deterministic parsing, schema validation, state transitions, or deduplication. Those tasks have known correct answers and should be owned by code.
- Do not apply the same review gate to every output. Gate fatigue is as dangerous as no gates.
- Do not add agent-to-agent coordination before the single-agent workflow has a clear contract and a reliable boundary between deterministic code and model judgment.
The tradeoff: more deterministic substrate means more upfront engineering and less flexibility than letting a model handle everything. A model call is faster to write than a schema validator. A prompt is quicker to modify than a routing configuration. But the engineering cost pays for itself when a workflow repeats, crosses a system boundary, runs on a schedule, produces artifacts other systems depend on, or touches a customer. It is not worth it for one-off research, exploratory analysis, or early-stage prototyping where the cost of failure is low and the value of flexibility is high.
If you are evaluating where your AI system draws the line between deterministic code and model judgment, start with a conversation about the operating layer around the model. Talk to Skaira
For more context on how we approach architecture and governance, see our method.